Load your spectrum data
数据分析的第一步就是导入数据。但是,在光谱数据的导入过程中往往存在以下问题,影响数据的分析过程,如①不同的文件格式让不同的数据导入很复杂;②难以批量导入整个文件夹的光谱数据。为了让数据导入的过程更加简单易操作,本文使用python构建了一些工具函数,可以实现不同格式的单张光谱/光谱数据文件夹的数据导入,并且可以存储经过处理的光谱数据为.csv文件格式,方便后续分析。
0. 写在前面
“写在前面”是本系列博客的特殊章节,会事先声明使用函数的注意事项,避免因为库函数未安装等原因使用失败;同时会列举该博客包含的函数名及其作用,方便读者索引。
在数据导入过程中,有两个较不常用的python工具包需要读者事先安装,以此正常使用函数功能,分别为:
1
2
pip install natsort
pip install sif_parser
其中natsort的作用为将文件夹中的文件名按照自然顺序进行排序,sif_parser的作用为读取Andor光谱仪的sif光谱文件。两个工具包的官方文档如下,欢迎查看:
- natsort:natsort · PyPI
- sif_parser:sif-parser · PyPI
本文更新的函数列表如下:
| 函数名 | 函数作用 |
|---|---|
| Ramanshift_Cal | 波长-拉曼位移转换器,将波长转换为拉曼位移 |
| Wavelength_Cal | 拉曼位移-波长转换器,将拉曼位移转换为波长 |
| get_spectrum | 读取光谱文件(暂时支持.asc,.txt,.csv,.sif格式的光谱文件读取),生成DataFrame格式光谱数据 |
| get_spectrum_from_folder | 从文件夹中批量读取光谱文件(排序按照文件名称顺序) |
| save_spectrum | 保存光谱数据 |
| plot_spectrum | 使用光谱数据绘制简单的光谱图像 |
1. 函数定义及使用
在本系列中,“函数定义及使用”板块将直接列举使用的python库、定义的函数、使用示例三个板块,如果读者不想了解函数实现细节,直接将该板块的代码复制到自己的python环境当中,并且将使用示例稍作修改即可。
本文使用的python库函数如下:
1
2
3
4
5
6
import sif_parser
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import os
from natsort import natsorted
本文提及的函数定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
def Ramanshift_Cal(lambda_out,lambda_in):
Raman_shift = 10**7/lambda_in - 10**7/lambda_out
return Raman_shift
def Wavelength_Cal(raman_shift,lambda_in):
Wavelength = 1/(1/lambda_in-raman_shift/10**7)
return Wavelength
def get_spectrum(data_path, begin_label,end_label,laser_wavelength=785,x_axis="Raman shift"):
if data_path.endswith('.csv') or data_path.endswith('.asc'):
# csv文件,asc文件读取(分隔符为,)
data = pd.read_csv(data_path,names=[x_axis,"Intensity"])
data = data.iloc[begin_label:end_label] # 切割数据
return data
elif data_path.endswith('.txt'):
# txt文件读取(分隔符为\t)
data = pd.read_csv(data_path,names=[x_axis,"Intensity"],delimiter='\t')
data = data.iloc[begin_label:end_label] # 切割数据
return data
elif data_path.endswith('.sif'):
# sif文件读取
(data_sif, __) = sif_parser.utils.parse(file_name)
data_sif[:,0] = Ramanshift_Cal(data_sif[:,0],laser_wavelength) # 转换为Raman shift
data = pd.DataFrame(data_sif,columns=[x_axis,"Intensity"])
data = data.iloc[begin_label:end_label]
return data
def get_spectrum_from_folder(data_path,file_type,begin_label,end_label,laser_wavelength=785,x_axis="Raman shift"):
# 读取文件夹下的光谱文件
file_list = os.listdir(data_path)
file_list = natsorted(file_list)
# print(file_list)
data_list = []
for file in file_list:
if file.endswith(file_type):
data = get_spectrum(os.path.join(data_path,file),begin_label,end_label,laser_wavelength,x_axis)
data_list.append(data)
return data_list
def save_spectrum(data,save_path):
data.to_csv(str(save_path),index=False,header=None)
def plot_spectrum(x,intensity,x_label="Raman shift"):
plt.plot(x,intensity)
plt.xlabel(x_label)
plt.ylabel("Intensity")
函数使用示例如下:
- 读取单张光谱,并观察数据
1
2
3
4
5
6
7
8
9
10
11
12
# 读取和保存光谱所需参数,可修改
data_path = r"..\data\spectrum_1.sif"
begin_label = 200
end_label = 2000
laser_wavelength = 785 # 读取Andor的sif文件软件所需,因为要进行波长转换
x_axis = "Raman shift" # 如果读取的光谱横坐标为"Wavelength",则该部分可修改为"Wavelength"
# 读取光谱
data=get_spectrum(data_path, begin_label,end_label,laser_wavelength,x_axis)
# 观察数据
data.head()
- 绘制光谱数据,并存储处理后的光谱数据
1
2
3
4
5
6
7
8
9
10
11
12
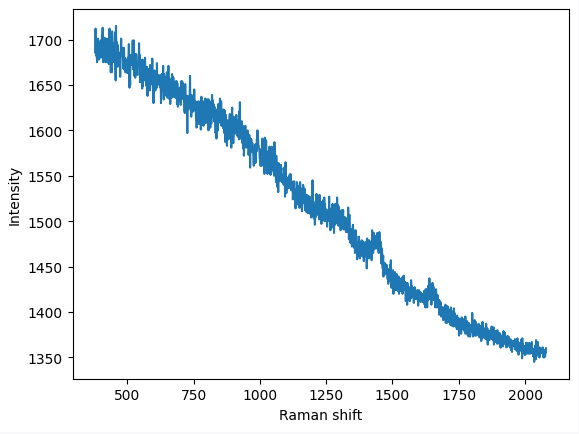
# 保存光谱为csv文件格式,并绘制简单的光谱图像观察效果
shift = data["Raman shift"]
intensity = data["Intensity"]
# intensity = preprocessing(intensity) # 假设光谱数据经过预处理
# 绘制简单的拉曼光谱图像
plot_spectrum(shift,intensity)
# 存储数据
data = pd.DataFrame({"Raman shift":shift,"Intensity":intensity})
save_path = r"..\data\sprectrum.csv"
save_spectrum(data,save_path)
绘图效果如下:
- 从文件夹中读取光谱数据
1
2
3
4
5
6
7
8
9
10
# 从文件夹中读取光谱文件
data_path = r"..\data"
file_type = ".sif"
begin_label = 200
end_label = 2000
laser_wavelength = 785 # 读取Andor的sif文件软件所需,因为要进行波长转换
x_axis = "Raman shift"
data_list=get_spectrum_from_folder(data_path,file_type,begin_label,end_label,laser_wavelength,x_axis)
data_list[0] # 代表数据列表中的第一个光谱数据
2. 函数实现细节
在本系列中,“函数实现细节”重点解决“为什么”的问题,即对于部分的代码进行解释,让读者能够理解部分代码的使用逻辑,从而方便自己修改部分函数,实现自己的功能。
2.1 文件格式问题
在前言中提到,光谱数据的导入过程中,首先要处理的问题即光谱格式不统一的问题。大多数光谱仪可以导出常见的文件格式,如.csv文件、.asc文件或者.txt文件,这几种文件都可以用记事本或者Excel正常打开,读者也可以选择使用Excel进行数据处理。但是一些光谱仪软件会导出软件特定的光谱文件格式,如Andor光谱仪会自动保存为.sif文件的格式,虽然其自带软件当中含有格式转换的功能,但是如果要开发集成的软件对于光谱进行处理,显然不能只依赖光谱仪自带的软件。所以,导入不同格式的光谱文件,并且统一输出格式,是一个很关键的问题。
幸好,python库函数具有“只有你想不到,没有我做不到”的特点。通过检索,可以发现Andor中.sif格式的光谱文件可以用库函数进行读取,无需自己编写,所以只要在函数get_spectrum中加入文件格式的判断,再针对不同类型的文件格式进行数据读取即可。不同类型的数据对应的读取方法如下:
- 针对分隔符不同的常规文件,采用pandas库函数中的read_csv进行读取即可;
- 针对Andor的.sif光谱文件,使用sif_parser进行读取,需要注意的是,该光谱文件的横坐标存储的是波长数据,所以在其中加入了波长-拉曼位移转换的步骤。如果想要保留波长数据,可以使用拉曼位移-波长转换器或者对于原始函数进行修改,从而保存原始波长数据。
2.2 有关输入参数
细心的读者也许会发现,为什么函数的参数经常会发生变化,有时候会直接使用data来表示光谱数据(如函数save_spectrum),而有时候又要使用x和intensity分别表示光谱数据的横轴和纵轴,这不是多此一举吗?下面说明原因:
使用data来表示数据,一般在数据的存储或者读取的部分,此时数据作为一个整体(在python中即为DataFrame)而存在,便于直接存储,同时也方便分割不同的数据。
使用x和intensity分别表示数据的横轴和纵轴,则一般出现在数据处理和展示的过程中,此时x和intensity之间一般没有相互影响。如对于波长-拉曼位移进行转换,和光谱的intensity无关,而光谱的去基线、降噪等处理方式,又和其横轴没有关系;而且在绘图过程中,常常碰到同样横轴对应许多不同曲线的情况,此时也需要将两者分开才好。
基于以上原因,在本系列包含的大部分博客,即编写数据处理的函数时,将统一采用x(默认为Raman shift)和intensity来作为输入数据,并且同样分x和intensity进行输出,方便函数之间互相引用。
3. 待更新
数据导入部分到此暂告一段落,通过以上函数已经能够实现常见光谱文件的读取。当然,一些情况仍旧没有考虑周全,暂时放在以下待更新列表当中:
- 多光谱数据文件的导入;
- 光谱绘图风格的设置;
如若有其他问题,欢迎发送邮件交流!
换电脑test.